pr(R) = 1/r*exp(-R/r)We can solve this for an expected valuation, x, of some arbitrary stock after time, t.
n(x|t) = ∫ pr(R) δ(x-Rt) dRThis reduces to the marginal distribution:
n(x|t) = 1/(rt) * exp(-x/(rt))In general, the growth of a stock only occurs over some average time, τ, which has its own Maximum Entropy probability distribution:
p(t) = 1/τ *exp(-t/τ)So when the expected growth is averaged over expected times we get this integral:
n(x) = ∫ n(x|t) p(t) dtWe have almost solved our problem, but this integration reduces to an ugly transcendental function K0 otherwise known as a modified Bessel function of the second kind and order 0.
n(x) = 2/(rτ) * K0(2*sqrt(x/(rτ) ))Fortunately, the K0 function is available on any spreadsheet program (Excel, OpenOffice, etc) as the function BESSELK(X;0).
Let us try it out. I took 3500 stocks over the last decade (since 1999), and plotted the histogram of all rates of return below.
 The red line is the Maximum Entropy model for the expected rate of return, n(x) where x is the rate of return. This has only a single adjustable parameter, the aggregate value rτ. We line this up with the peak which also happens to coincide with the mean return value. For the 10 year period, rτ = 2, essentially indicating an average doubling in the valuation of the average stock. This doesn't say anything about the stock market as a whole, which turned out pretty flat over the decade, only that certain high-rate-of-return stocks upped the average (much like the story of Bill Gates entering a room of average wage earners).
The red line is the Maximum Entropy model for the expected rate of return, n(x) where x is the rate of return. This has only a single adjustable parameter, the aggregate value rτ. We line this up with the peak which also happens to coincide with the mean return value. For the 10 year period, rτ = 2, essentially indicating an average doubling in the valuation of the average stock. This doesn't say anything about the stock market as a whole, which turned out pretty flat over the decade, only that certain high-rate-of-return stocks upped the average (much like the story of Bill Gates entering a room of average wage earners).The following figure shows a Monte Carlo simulation where I draw 3500 samples from a rτ value of 1. This gives an idea of the amount of counting noise we might see.
 I should point out that the MaxEnt model shows very little by way of excessively fat tails at high returns. A stock has to both survive a long time and grow at a rapid enough rate to get too far out in the tail. You see that in the data as only a couple of the stocks have returns greater than 100x. I don't rule out the possibility of high-return tails but we would need to put even more disorder in the pr(R) distribution than the MaxEnt provides for a mean return rate. The actual data seems a bit sharper and has more outliers than the Monte Carlo simulation, indicating some subtlety that I probably have missed. Yet, this demonstrates how to use the Maximum Entropy Principle most effectively -- you should only include the parameters that you can defend. From this minimal set of constraints you observe how far this can take you. In this case, I could only defend some concept of mean in rτ and then you get a distribution that reflects the uncertainty you have in the rest of the parameter space.
I should point out that the MaxEnt model shows very little by way of excessively fat tails at high returns. A stock has to both survive a long time and grow at a rapid enough rate to get too far out in the tail. You see that in the data as only a couple of the stocks have returns greater than 100x. I don't rule out the possibility of high-return tails but we would need to put even more disorder in the pr(R) distribution than the MaxEnt provides for a mean return rate. The actual data seems a bit sharper and has more outliers than the Monte Carlo simulation, indicating some subtlety that I probably have missed. Yet, this demonstrates how to use the Maximum Entropy Principle most effectively -- you should only include the parameters that you can defend. From this minimal set of constraints you observe how far this can take you. In this case, I could only defend some concept of mean in rτ and then you get a distribution that reflects the uncertainty you have in the rest of the parameter space.The stock market with its myriad of players follows an entropic model to first-order. All the agents seem to fill up the state space so that we can get a parsimonious fit to the data with an almost laughably simple econophysics model. For this model, the distribution curve on a log-log plot will always take on exactly that skewed shape (excepting for statistical noise of course) -- it will only shift laterally depending the general direction of the market.
The stock market becomes essentially a toy problem, no different than the explanation of statistical mechanics you may encounter in a physics course.
Has anyone else figured this out?
[EDIT]
Besides the slight fat-tail, which may be due to potential compounding growth similar to that found in individual incomes, the sharper peak may also have a second-order basis. This could result from a behavior called implied correlation which measures the synchronized behavior among stocks in the market. According to recent measurements, the correlation has hit all-time highs (the last around October 5). Qualitatively a high correlation would imply that the average growth rate r would show much less dispersion in that variate, and the dispersion would only apply to the length of time, t, that a stock rides the crest. Correlation essentially removes one of the parameters of variability from the model and the distribution sharpens up. The stock distribution then becomes the following simple damped exponential instead of the Bessel.
n(x) = 1/(rτ) * exp(-x/(rτ))The figure below shows what happens when about 40% of the stocks would show this correlation (in green). The other 60% show independent variability or dispersion in the rates as per the original model.
 I don't think this makes the collective stock behavior and more complex. I think it makes it simpler in fact. Implied correlation actually points to the future in the stock market. Dispersion in stock returns will narrow as all stocks move in unison. It makes it even more of a toy, with computers potentially dictating all movements.
I don't think this makes the collective stock behavior and more complex. I think it makes it simpler in fact. Implied correlation actually points to the future in the stock market. Dispersion in stock returns will narrow as all stocks move in unison. It makes it even more of a toy, with computers potentially dictating all movements.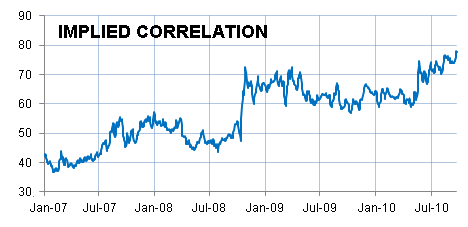
References
I personally don't deal with the stock market, preferring to watch it from afar. I found a few papers that try to understand this effect, but most just try to brute force fit it to various distributions.
- Analysis of same data from Seeking Alpha
- This paper is close but no cigar. It looks like they "detrend" the data to get of the skew, which I think misses the point :
"Microscopic origin of non-Gaussian distributions of financial returns" (2007) - This book has info on the Bessel distribution:
"Return distributions in finance", J. Knight and S. Satchell - Interesting from an econophysics perspective.
- This book appears worthless:
"Fat-Tailed and Skewed Asset Return Distributions", S.T. Rachev, F.J. Fabozzi, C Menn